
In Kubernetes pod is the smallest deployable unit of workload. So the obvious question :
“Where should the pods be deployed?”
Pods always execute inside a Node.
But but.. there are so many Nodes - which one should node should I deploy this pod to ??!
Hello - “Kubernetes Scheduler”
Let’s break down how the Kubernetes Scheduler works and the way it chooses a node in plain english with an analogy.
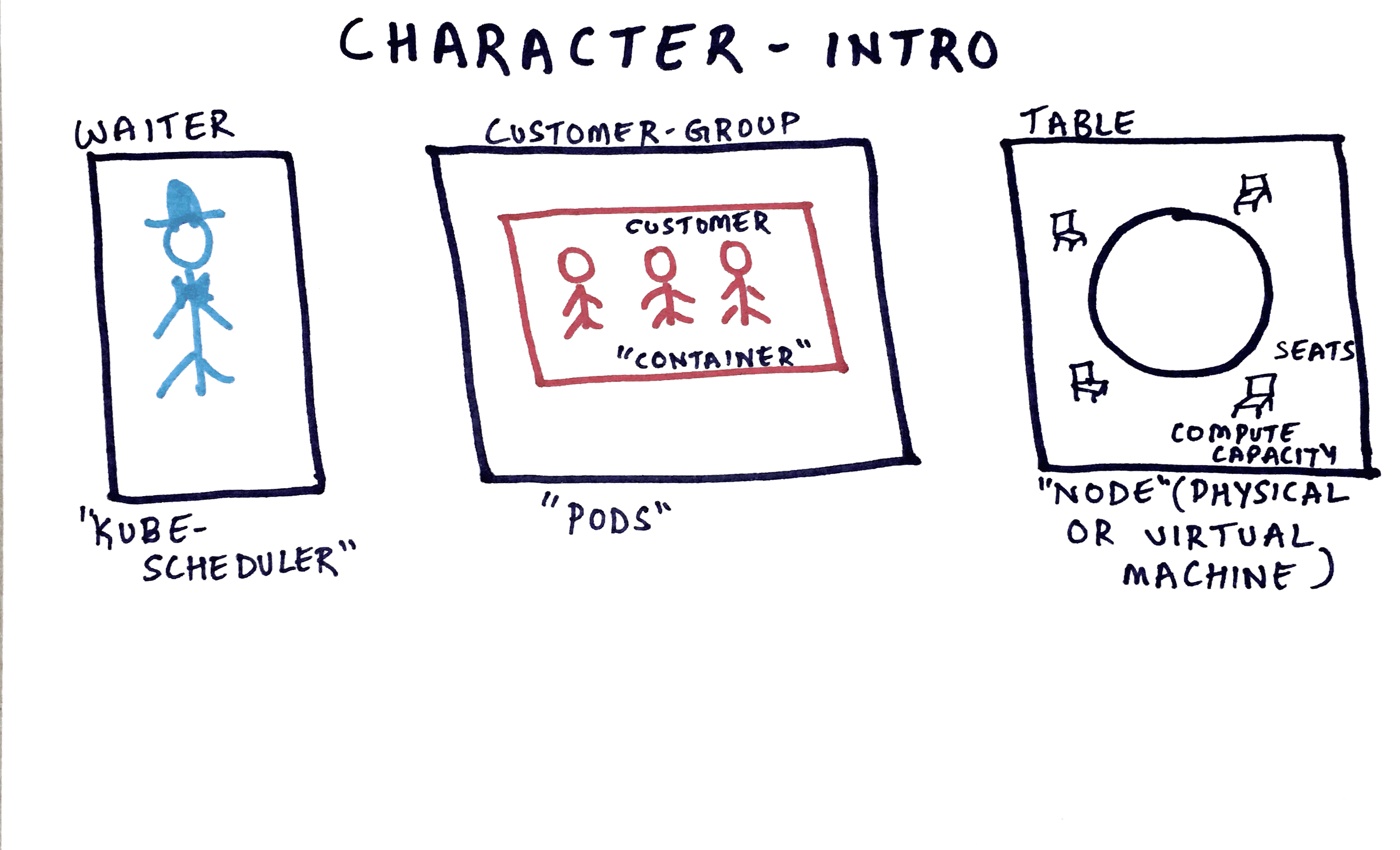
Lets say we have a “social-restaurant” where we have several tables and several seats around each table, lots of customers and a waiter for the hotel. “Social-restaurant” meaning different set of customers can sit around the same table, if there are enough seats and all conditions are met.
Table = Node (VM or a Physical Machine)
Seats = Resources availability on the VM
Waiter = Kube-Scheduler
Customer-Group = Pod
A single customer inside the group = Container
1. Resource requirements and availability
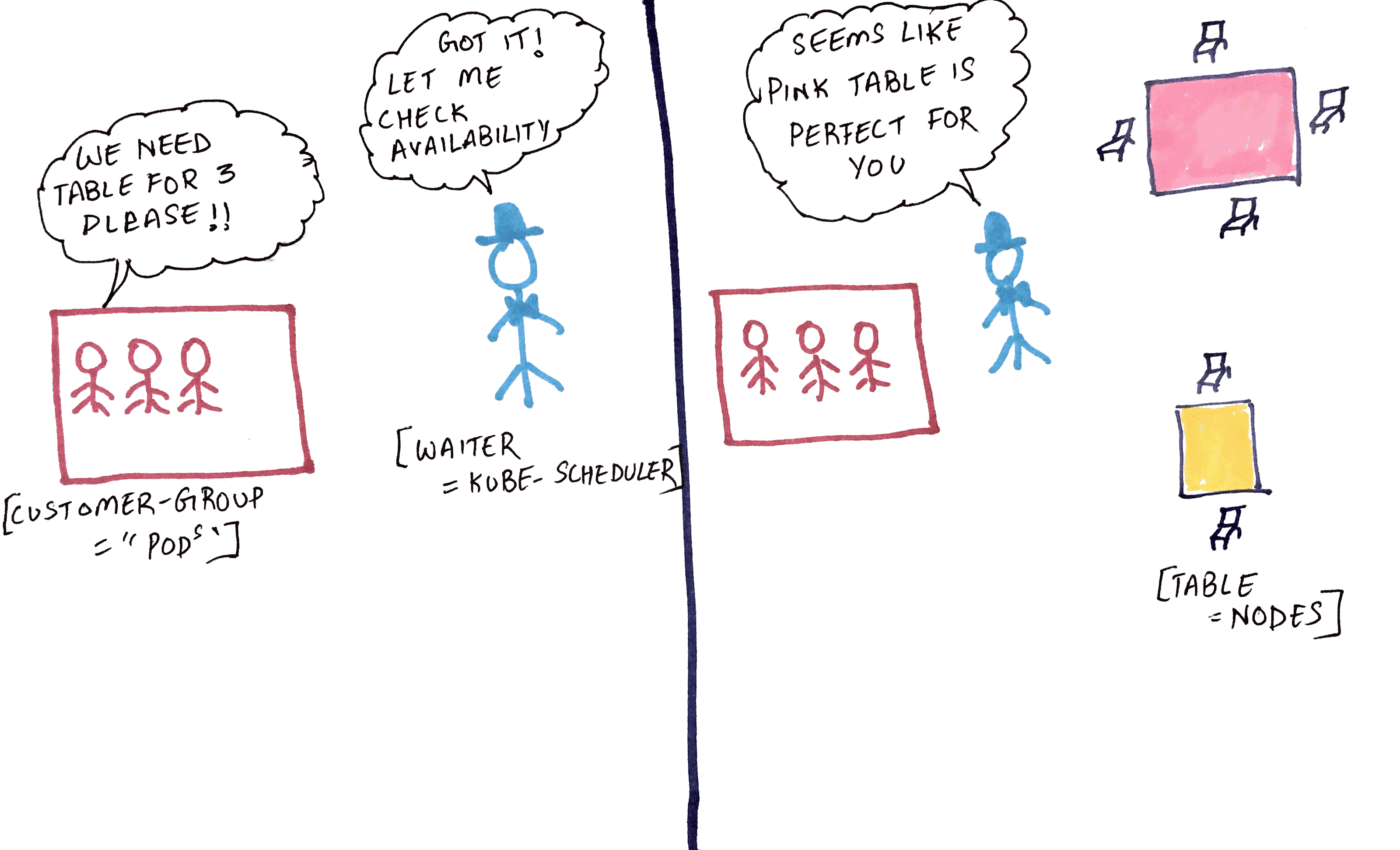
A Customer-Group comes into the restaurant and makes a simple request for a table to be seated. The waiter analyzes the requirement of the Customer-Group and looks at how many Seats they would need. He then looks through all the available tables, filters the tables that cannot be “scheduled” and assigns (binds) them a table which would meet their Seating requirement.
This is the basic kind of scheduling - where the kube scheduler constantly watches the API server to see if there are any pods which are unscheduled. Looks through the resource requirement for each of the container inside the pods.
Remember the containers are the ones which have the resource requirement in the spec not the pods themselves.
In the example below we have a CPU and Memory requirement under the container spec for the pod deployment. Requirements are 500 millicpu and an 128 MiB of memory.
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
resources:
requests:
memory: "128Mi"
cpu: "500m"
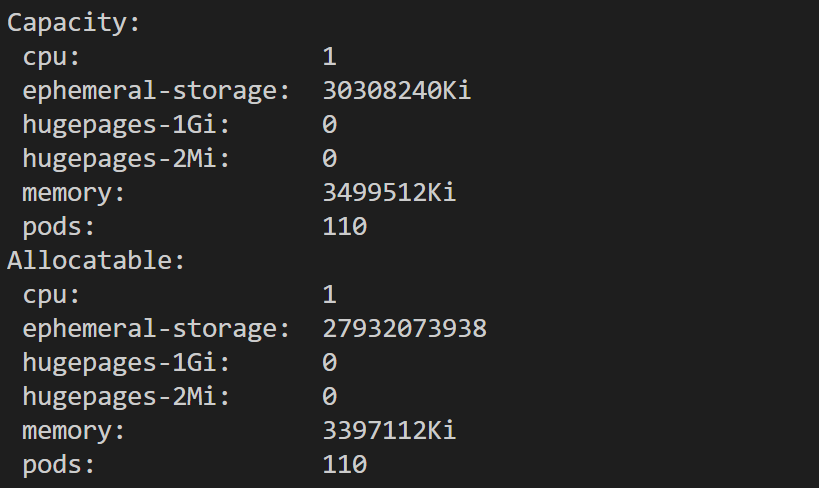
Now let’s take a look at one of the nodes (restaurant tables) to ensure they have capacity. The way we would do that is run the following command :
kubectl describe nodes <node-name>
which outputs all the properties of the nodes, but the ones we are interested are the Capacity and Allocatable.
Remember CPU and memory are not the only filter criteria, there are lots more like persistent storage, network port requirements. Detailed list here.
2. Node Selector
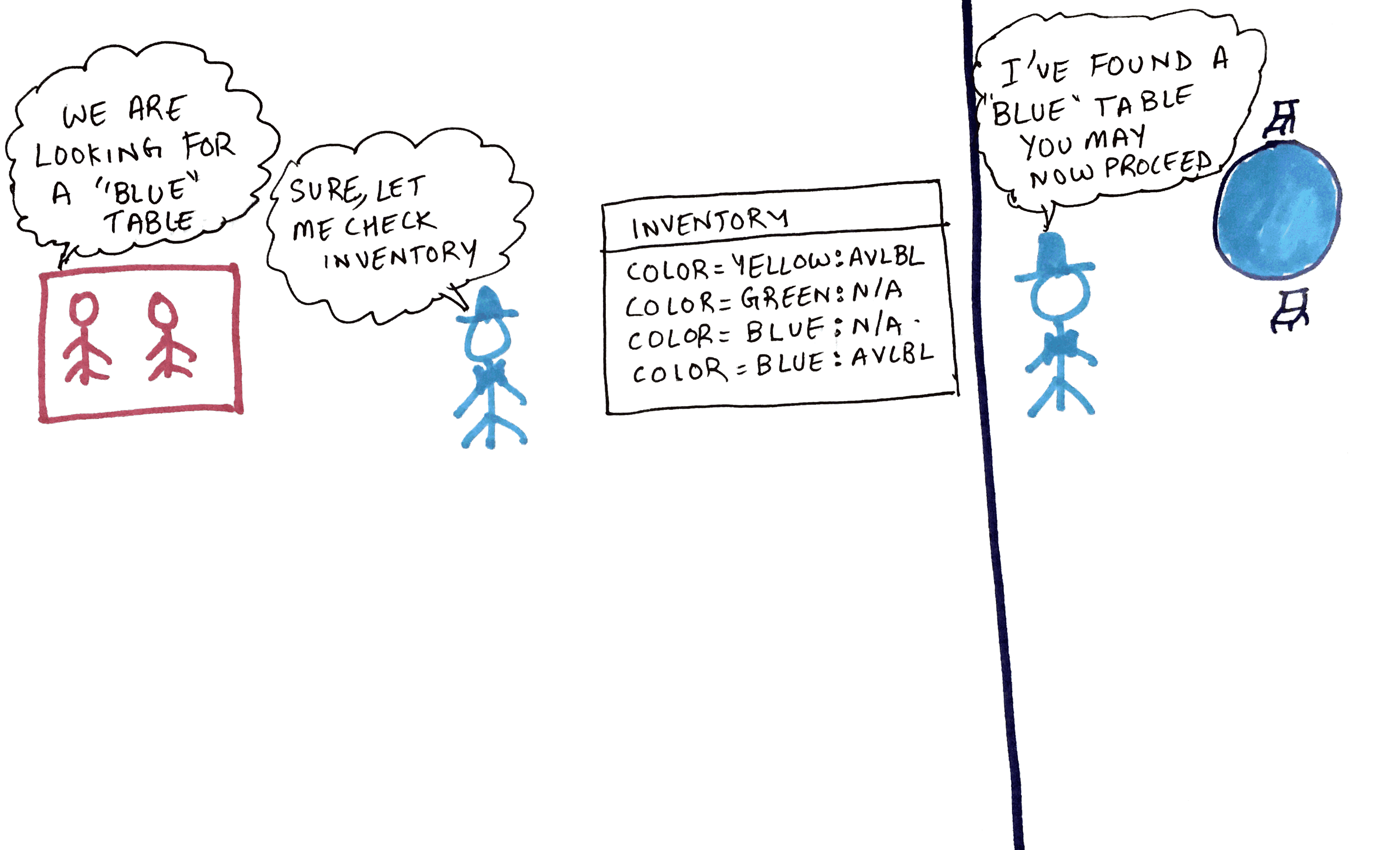
Another Customer-Group come in to the restaurant with a requirement to be placed in any table which is “blue”. The waiter looks through his inventory and finds all the tables which has a label of blue and assigns the Customer-Group to the appropriate table
In this scenario the pod has a nodeSelector (key-value pair) specified which requests the pod to be deployment to any node which matches the key-value pair.
Here is how the new YAML file will look like:
apiVersion: v1
kind: Pod
metadata:
name: nginx-blue
spec:
containers:
- name: nginx
image: nginx:1.7.9
nodeSelector:
color: blue
In order to query all my nodes to check if we have the label “blue”, we run the following command.
kubectl get nodes --show-labels
From the list we can see that “worker-2” has a label of color=blue. Also there are several built-in labels which Kubernetes provides us with too.

Great ! If you now deploy this, the scheduler automatically assigns it to the right node. (worker-2). We can confirm this by running the following command.
kubectl get pod -o wide
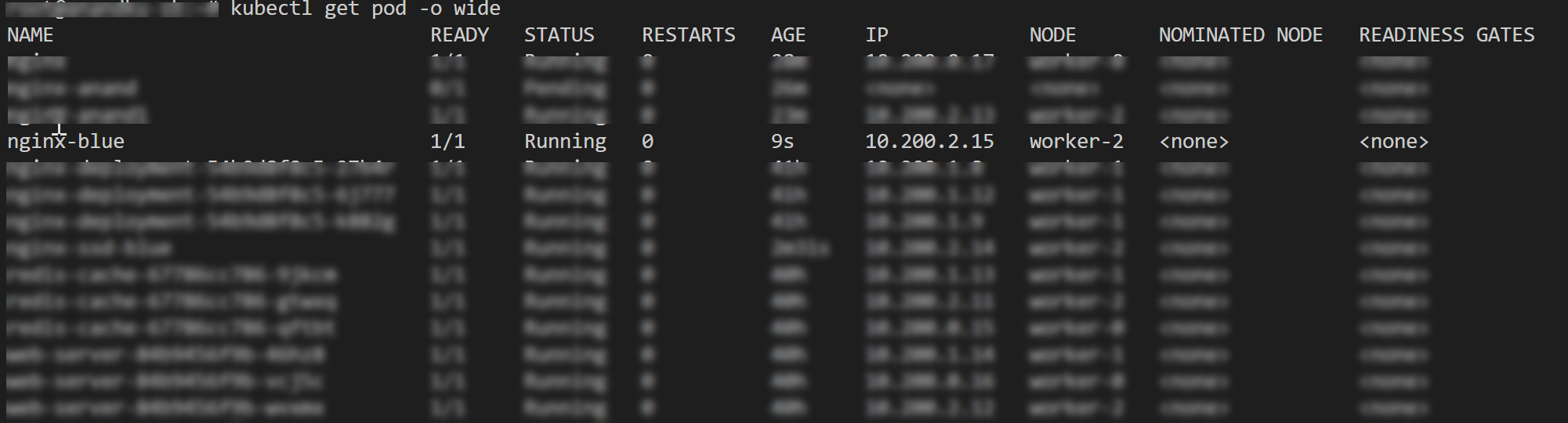
Note that if you did not have a node with the appropriate label the deployment would be Pending.
3. Node affinity and anti-affinity
Node affinity and anti-affinity are a lot like node selectors, but it gives you more flexibility by supporting expressive language and soft/hard preference rather than just a hard requirement.
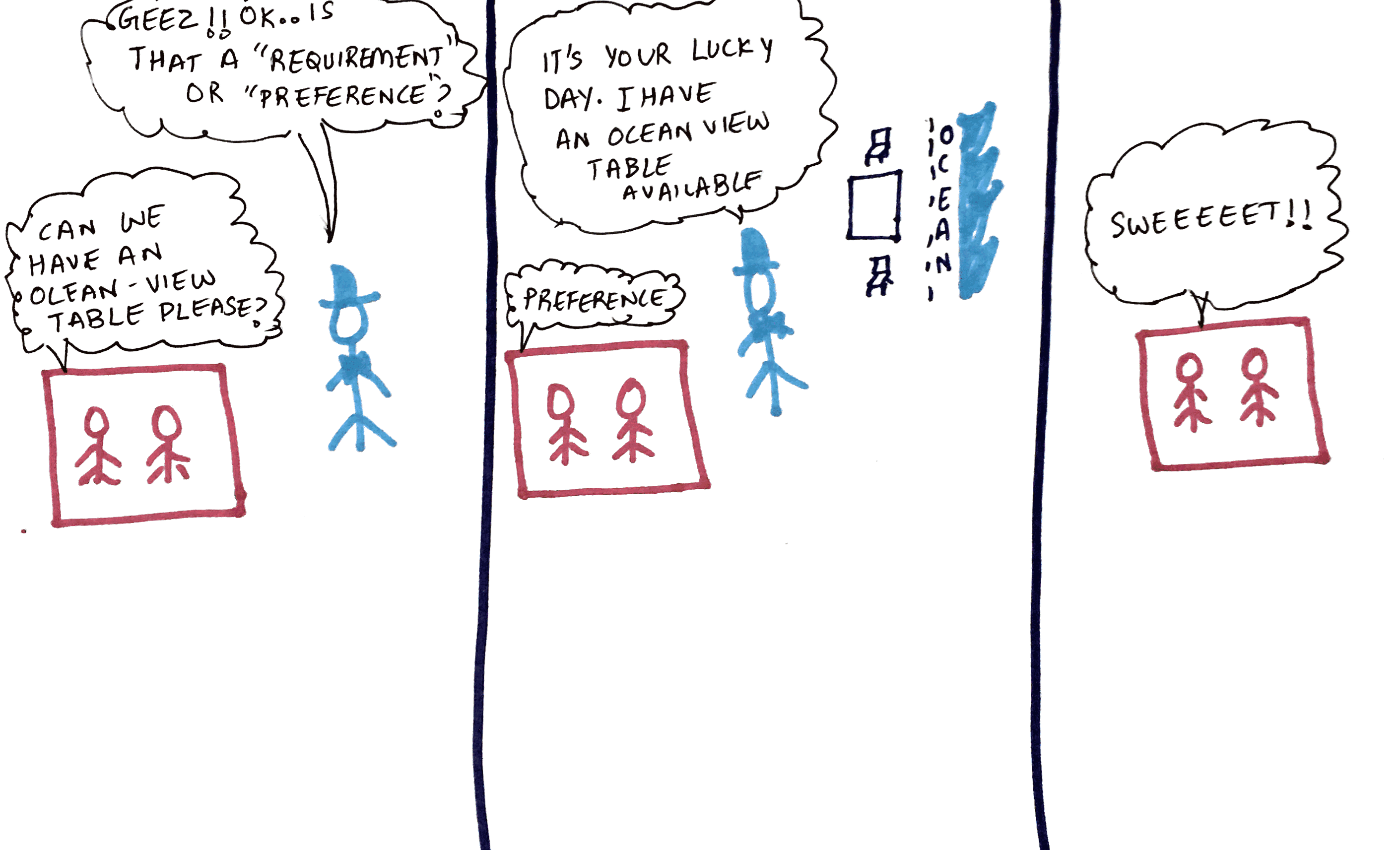
Lets say another Customer-Group come in to the restaurant . They have a preference to be placed in any table which is “ocean-view”, but its not required. The waiter looks through his inventory and finds all the tables which has a label of “ocean” and assigns the Customer-Group to the appropriate table
In this example the pod has a nodeAffinity defined which states that we prefer a “node” which matches the key value pair –> view : ocean ( and we do that by the matchExpressions below)
There are two options here :
-
preferredDuringSchedulingIgnoredDuringExecution : which means that the nodes that match the criteria will be preferred, but not guaranteed when the allocation to the node happens.
IgnoredDuringExecution - If you remove or change the label of the node after the pod is scheduled, the pod won’t be removed. In other words, the affinity selection works only at the time of scheduling the pod but not at execution
-
requiredDuringSchedulingIgnoredDuringExecution : which means that the nodes that match the criteria will be required when selecting the node. IgnoredDuringExecution is the same as before.
apiVersion: v1
kind: Pod
metadata:
name: nginx-oceanview
spec:
containers:
- name: nginx
image: nginx:1.7.9
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: view
operator: In
values:
- ocean
The operator in this case can also be other values such as In, NotIn, Exists, DoesNotExist, Gt, Lt. NotIn and DoesNotExist will create the opposite effect of nodeAntiAffinity
4. Pod affinity and anti-affinity

Another vegan girl-gang Customer-Group come in to the restaurant . They have a requirement not to be placed in any table which contain seats which are already occupied by meat eaters. They are a little more choosy - they also want to be seated in tables which contains seats which are already occupied by only girls. In other words they have a non-affinity towards meat-eaters, but have an affinity towards girls.
Lets take a real world scenario where you have a set of redis-cache and web-server deployments. Here are the conditions:
- You want the redis-cache pods deployed as close to the web-servers pods as possible (podAffinity)
- You don’t want two redis-cache pods in the same node (podAntiAffinity)
- You don’t want to deploy two web-server pods in the same node (podAntiAffiinity)
- You want these rules to hold good for the scope of a node. (topology)
Here is how the redis-cache deployment YAML would look. :
apiVersion: apps/v1
kind: Deployment
metadata:
name: redis-cache
spec:
selector:
matchLabels:
apptype: redis-cache
replicas: 3
template:
metadata:
labels:
apptype: redis-cache
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: apptype
operator: In
values:
- redis-cache
topologyKey: "kubernetes.io/hostname"
containers:
- name: redis-server
image: redis:3.2-alpine
In the example above:
- In the example above you see that the redis-cache label (apptype=redis-cache) is added to every pod which gets deployed as part of this deployment
- The podAntiAffinity is described such that no two redis-cache pods are deployed inside the same server. This is defined by the built-in topology “kubernetes.io/hostname” which means its a single node. This can also be extended to zones or any other legal-key if required.
Awesome - once you deploy this - here is what you would get :

Now, lets take a look at the web-server deployment YAML file
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-server
spec:
selector:
matchLabels:
apptype: web-server
replicas: 3
template:
metadata:
labels:
apptype: web-server
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: apptype
operator: In
values:
- web-server
topologyKey: "kubernetes.io/hostname"
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: apptype
operator: In
values:
- redis-cache
topologyKey: "kubernetes.io/hostname"
containers:
- name: web-app
image: nginx:1.12-alpine
In the example above:
- In the example above you see that the web-server label (apptype=web-server) is added to every pod which gets deployed as part of this deployment
- The podAntiAffinity is described such that no two web-server pods are deployed inside the same server. This is defined by the built-in topologyKey “kubernetes.io/hostname” which means its a single node. This can also be extended to zones or any other legal-key if required.
- The podAffinity is described such that the web-server pods are deployed as close to the redis-cache as possible.
Once you deploy this - we got what we were aiming for - 3 web-servers and 3 redis-cache servers - one copy of each on one node !

5. Taint and Tolerations
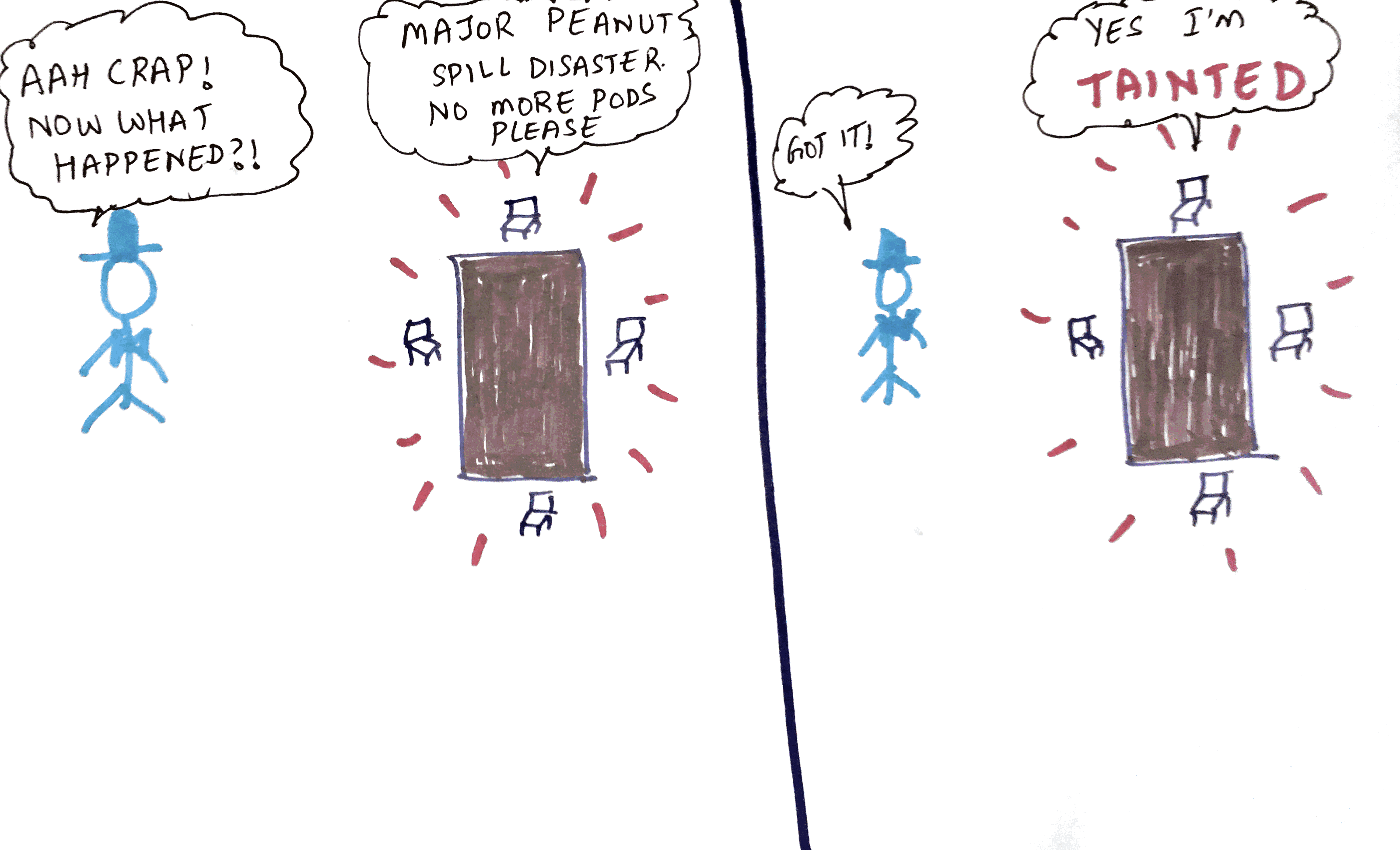
This time around the restaurant got one of the tables “tainted” with a peanut spillage disaster. So they have said no new Customer-Groups will be scheduled on this table to avoid allergic reactions. So any new Customer-Groups are placed on every other table except this tainted one.
So far we have been looking at scheduling from a pod perspective. But what if the other way around the node decides not to schedule anymore new pods ? This is where taints come in. Once you taint a node you have two options :
- NoSchedule - This means no new pods should be scheduled on this pod once its tainted. *unless they have a toleration
- NoExecute - Existing pods will be evicted from the pod once its tainted. *unless they have a toleration (we will talk about tolerations in just a minute)
So how do we taint a node ?
kubectl taint nodes <nodename> mytaintkey=mytaintvalue:NoSchedule
Once we have this set the node is now tainted with the following key value pair (mytaintkey=mytaintvalue). So no new pods can be scheduled.
But what if you want to evict the existing pods from the nodes ?
kubectl taint nodes <nodename> mytaintkey=mytaintvalue:NoExecute
This will evict all pods from the current node and move them to another available node.
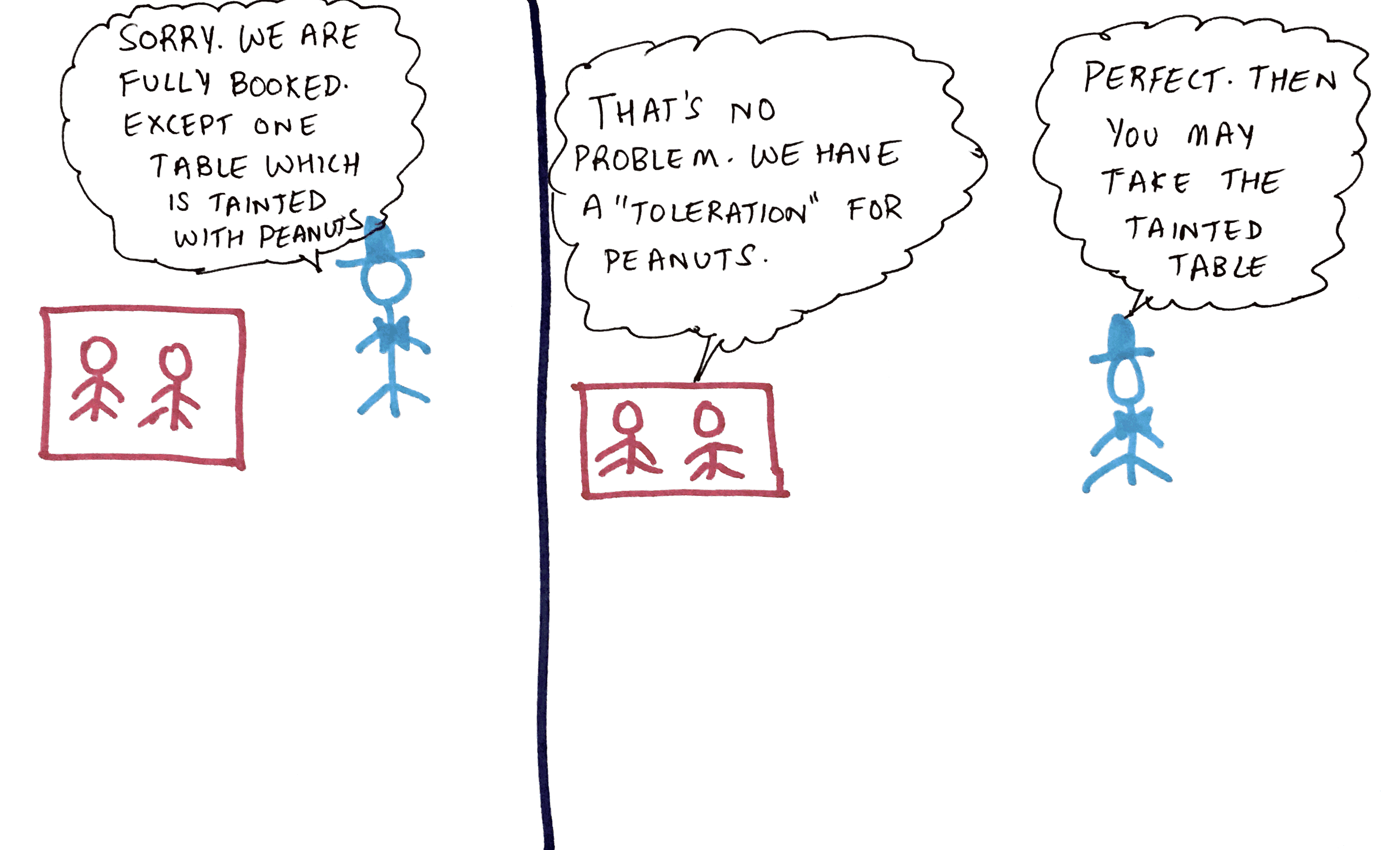
But after a while a Customer-Group comes along and says - “Oh that’s fine. We have “toleration” for peanut allergies. So please proceed and place us in the “tainted” table”. The Kube scheduler verifies their toleration and places them in the tainted table
Now if the pod has a toleration for the taint key value that the node has specified, then this pod will get exempted from the taint and will be placed on the node if necessary.
apiVersion: v1
kind: Pod
metadata:
name: web-server
spec:
containers:
- name: web-app
image: nginx:1.12-alpine
tolerations:
- key: "mytaintkey"
operator: "Equal"
value: "mytaintvalue"
effect: "NoExecute"
credits to Carson Anderson for planting this idea-seed from his awesome Kube-Decon talk




Leave a comment